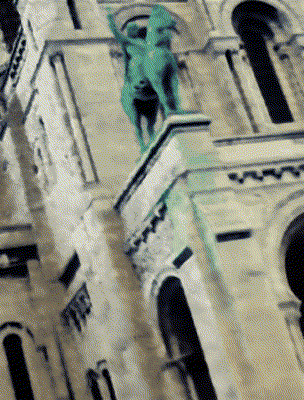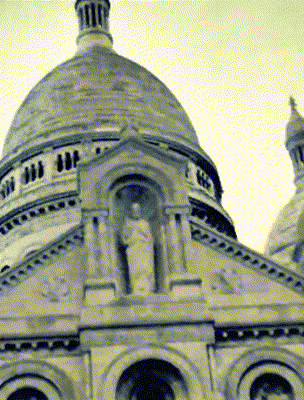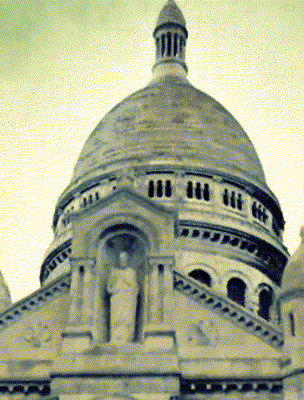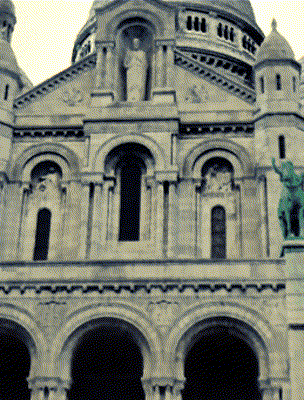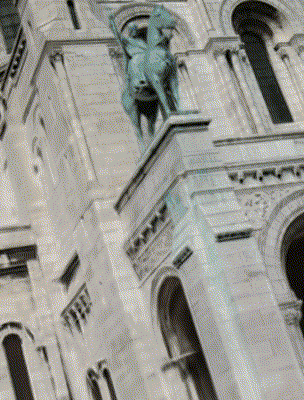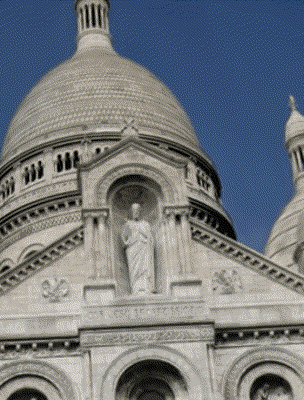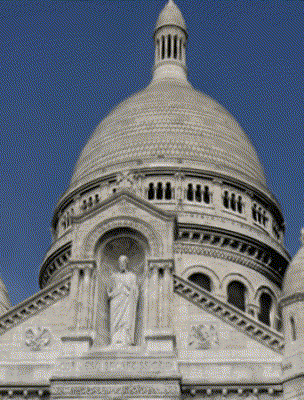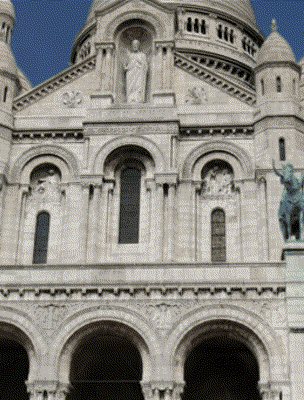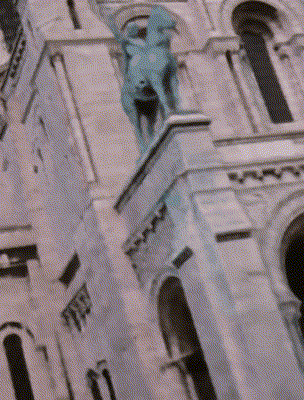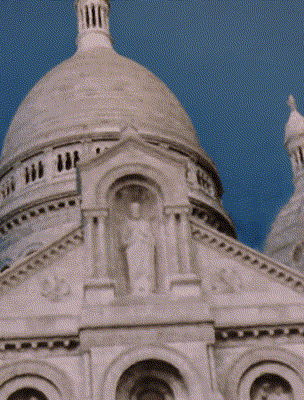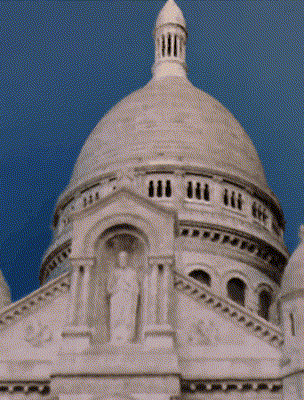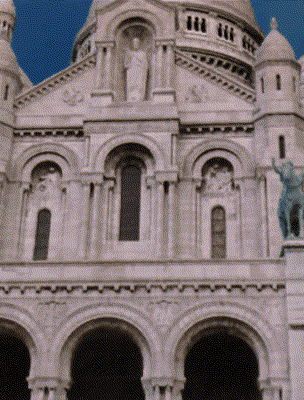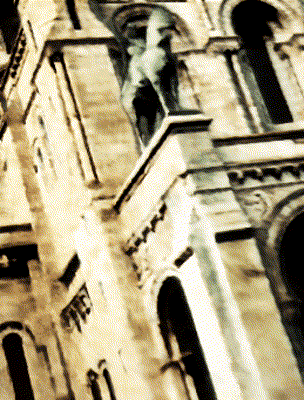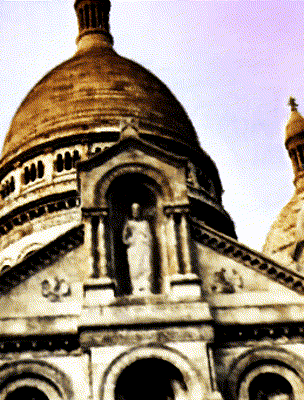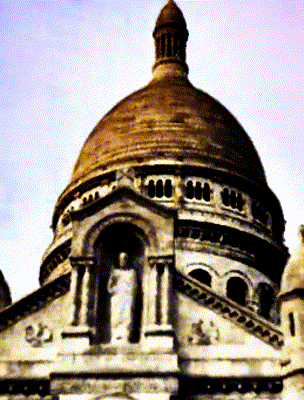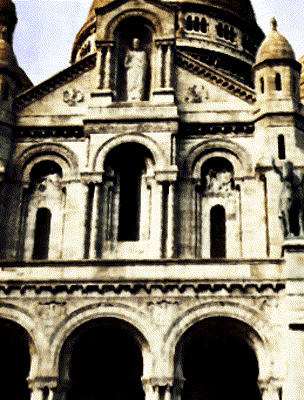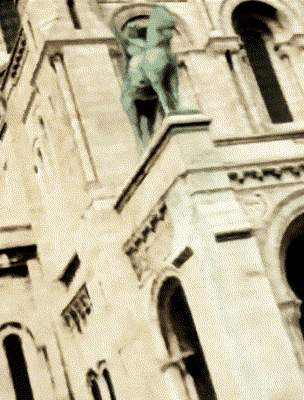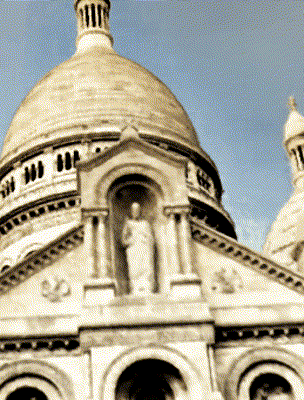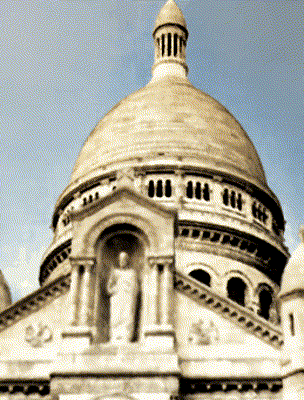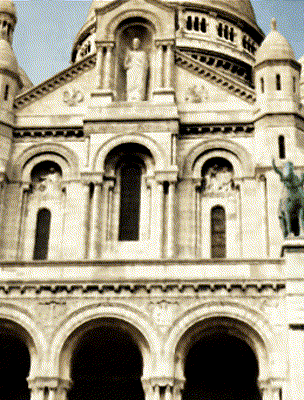Ours

CR-NeRF [Yang 2023]

Target Appearance Photo 1

Ours

CR-NeRF [Yang 2023]

Target Appearance Photo 2

Ours

Ha-NeRF [Chen 2023]

Target Appearance Photo 3

Ours

Ha-NeRF [Chen 2023]

Target Appearance Photo 4